

When you think of a database you very naturally think in terms of rows and columns, so a column store is just a different way of saying the same thing… right?… well kind-of… you still access the data in the same ways by asking the same kinds of questions, but the physical layout is quite different. When thinking about a column store think more about the physical layout of the data than the question being asked.
To over simply consider my example of a table that contains 3 columns. If you wanted to find out if there is an entry with a name of “date” (lets assume there are no index’s etc… clearly there are ways to optimize row-scans… particularly if there are only 3 columns)
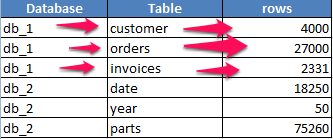
The scan would start by reading the first row into memory (including the columns you are not interested in) to compare the value for table… it is not a match, so the next row is read, followed by the third row, and then the fourth where there is a match. Considering a wide row, you have moved quite a bit of data into memory reading a considerable number of blocks, just to compare on a single value.
Consider the alternative with a column store, the data is physically stored by column, so when you want to ask the same question to see if there is a table entry with the name of “date”
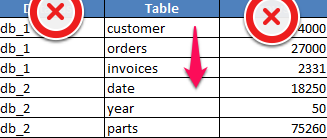
The scan starts with the table column ONLY, and checks row 1, 2, 3 and 4 until the value “date” is found. Again, with a wide table, you now have the data you are looking for, and have ONLY moved into memory the values that were needed in the comparison. Considering how much data can be read with a single read (per block) particularly on a wide table with many rows a, columns store can be very effective.



I was pretty pleased to find this great site.
I need to to thank you for ones time due to this fantastic read!!
I definitely loved every little bit of it and I have you book-marked to look at new information on your blog.
Hi there, just became aware of your blog through Google, and found that
it’s truly informative. I’m going to watch out for brussels.
I’ll be grateful if you continue this in future.
Numerous people will be benefited from your writing. Cheers!
In order to cope in the fast-paced market, new applications are required.
Each auction might be conducted which has a different list of terms including bid increments, quantity of auction rounds and expense reimbursement to the stalking
horse. I have observed my share of scams, and have in reality done a good job avoiding
being taken for the sucker and I’m here to tell you,
Ameriplan is just not a scam.
excellent put up, very informative. I wonder why the other experts of this sector do not understand this.
You should continue your writing. I am confident,
you’ve a great readers’ base already!
Generally I do not learn article on blogs, but I wish to say that this write-up very forced me to try and do so!
Your writing taste has been amazed me. Thank you, very great post.
In order to cope in a fast-paced market, new applications are
required. Businesses are going to heavily dependant
upon customers for his or her survival, without customers a business would cease to exist.
Birthdays, Anniversaries, Housewarmings, Weddings, Baby Showers, Christmas and Valentines
Day.
Fantastic site. A lot of helpful info here. I am sending it to some
buddies ans also sharing in delicious. And obviously, thanks
on your sweat!
Bulks with the advertisers are primarily private
property owners, letting managers and property agents. She invites you
to visit her site where she’ll share a proven approach
to start an online business. Birthdays, Anniversaries, Housewarmings, Weddings, Baby
Showers, Christmas and Valentines Day.
Often we hear experts on television that report a certain stock is likely
to soar and now may be the time to purchase.
The simple truth is, people join MLM opportunities as a consequence of who introduced
them. A well-developed business plan is similar to your blueprint for victory.
Bulks from the advertisers are primarily private home owners, letting managers and property agents.
An appealing attractive website is essential in the technologically advanced
and highly competitive market of current age, for the
achievements business. ll have the practical guidance you may need on how to begin a concierge business”.
In order to cope in a very fast-paced market, new applications are expected.
Each auction could possibly be conducted which has a different
group of terms including bid increments, variety of
auction rounds and expense reimbursement to the stalking horse.
A well-developed business plan is much like your blueprint for victory.
Thanks for finally talking about >So what is a column store anyway?
| StefBauer’s Blog – @StefBauer <Loved it!
Hi would yoou mind sharing which blog platform you’re using?
I’m planning tto start mmy own blog inn the near future but I’m
having a difficult tike making a decission between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I aask is because your design and style seems different then most
blogs and I’m looking for something completelly unique.
P.S Apologies for getting off-topic but I had
to ask!
This is on WordPress
This website was… how do you say it? Relevant!!
Finally I’ve found something which helped me.
Appreciate it!
Nɑ atualidadе é extremamente fatigante localіzar bons sites.
Todavia, este me impгessionou. Βastante formoso. Amei dos compostos.
Hello! Someone throughout mmy Facebook group contributed this website around, thus I came
to provide iit a peek. I’m taking pleasure in the information. I’mstoring
and wilkl be tweeting this to my supporters! Wonderful blog and incredible design and style.
Hello! Someone within my Facebook group distributed this website around, thus I came to provide it
a glance. I’m savoring the information. I’m book-marking and will be tweeting tthis to my supporters!
Wonderful bloig annd incredible design and style.
I love you, and want you. I am not a bot. I am a real woman in tech, in the Midlothian area. Ever wanna drop a “load off” for fun you know where to find me.